In 2021 when Netflix decided to move their systems to the cloud. They moved to AWS. In the new environment they realized workloads could be terminated and replaced at any point of time. This constrain lead to new way of testing the reliability of the solutions by randomly rebooting their workloads. Netflix created a tool called Chaos Monkey to automate the process and standardize system stability testing. Chaos Monkey helped Netflix finding wakeness in their systems and helped them build more reliable solutions.
Chaos engineering became a new practice on how to test large scale, distributed systems. Because these systems were so complex new approach was needed.
Chaos Engineering
The main reason for creating new testing methodology was to have a way to assess reliability of services, especially in case of a failure. It is done by injecting faults to the system causing it to fail. Once fail gets injected key point is to observe, monitor and (if needed) respond to the issue. The outcome is valuable knowledge helping to design architecture/processes to survive the failure.
Key points
- Improve service/application/solution resiliency and build processes helping react to failures
- Chaos principals have to be applied continuously
- Experiments should be created and organized by a dedicated Chaos Engineering Team
- Follow best practices for Chaos Testing
Goals of Chaos Engineering
- Gain expertise with monitoring tools
- Recognize outage patterns
- Learn how to assess the impact
- Quickly determine root cause
- Practice log analysis
Method
- Define a hypothesis
- Measure baseline behavior
- Inject fault
- Monitor the solution's reaction to the injected fault
- Document observations
- Identify key findings and plan improvements
Microsoft Azure Chaos Studio
At the end of 2021 Microsoft introduced Azure service called Chaos Studio. It was developed to help measure, understand and improve application and service resilience for real world incidents. It allows to simulate region failure, high CPU/Memory usage, networking issues. Running experiments can help validate solutions architecture to improve overall end-user experience in case of unexpected events.
Chaos experiments
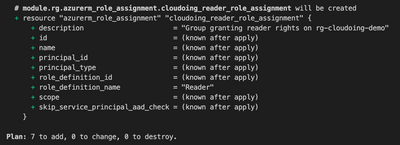
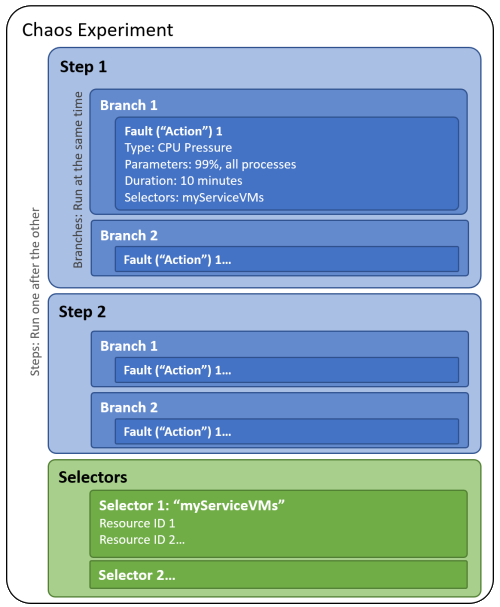
In Chaos Studio to design failures as experiments. Chaos experiment is an Azure resource contains a description of injecting failures as well as targets.
Experiment is defined in two sections:
- Selectors – group of targets receiving faults
- Logic – Description of the fault. The fault be for example intermittent loss of network connection or unexpected stress on CPU.
Base on the Chaos Experiment scenarios you can test how (or if) your solution will survive. By injecting simple faults you can constantly improve your infrastructure by challenging it to the new fault scenarios.
Faults and actions
Actions triggered as a part of experiment can be executed in two ways.
- Continuous – action (fault) will run for the predefined amount of time. This can be helpful when you want to test app availability (scaling) under heavy load.
- Run once (discrete) for – fault will be executed once. A perfect idea when you want to cause unexpected reboot and test auto healing functionality.
Chaos experiment scenarios can have multiple stages. Faults disrupting operations for a resource (or group of resources) can be injected in a controller manner. Time delays help to set up scenario by injecting “waits” without the faults injections. That time can be required to recover solution from a previous fault before injecting another one. A perfect way to test the multiple scenarios at once.
Actions (faults) can cause disruptions on many levels, starting from killing a process up to causing a fault on Azure service level. Some faults require a Chaos Studio agent to be installed on a target VM. Agent-based faults are required when the injected fault is executed on the system level (stress tests, memory pressure tests, process killing).
| VM | Network | AKS | Other |
|---|---|---|---|
| CPU pressure | DNS failure | AKS Chaos Mesh network faults | ARM virtual machine shutdown |
| Physical memory pressure | Network latency | AKS Chaos Mesh pod faults | ARM virtual machine scale set instance shutdown |
| Virtual memory pressure | Network disconnect | AKS Chaos Mesh stress faults | Cosmos DB failover |
| Disk I/O pressure (Windows) | Network disconnect with firewall rule | AKS Chaos Mesh IO faults | Azure Cache for Redis reboot |
| Disk I/O pressure (Linux) | Network security group (set rules) | AKS Chaos Mesh time faults | |
| Arbitrary Stress-ng stress | AKS Chaos Mesh kernel faults | ||
| Stop Windows service | AKS Chaos Mesh HTTP faults | ||
| Time change | AKS Chaos Mesh DNS faults | ||
| Kill process |
Availability of the failure scenarios is limited, you can see the up-to-date list in the faults library
Azure Chaos studio helps you improve resilience of your systems. It can also help you understand better the systems' behavior during and after the unexpected fault.
Sources
- https://www.gremlin.com/chaos-monkey/
- https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice/
- https://docs.microsoft.com/en-us/azure/chaos-studio/